Trait d'Union, A.A. CGR-GEMS
Amicale des Anciens de la Compagnie Générale de Radiologie et de General Electric Medical Systems
- Accueil
- Activités Culturelles
- Musée de la Marine
- Musée du Chocolat
- Tribunal de Commerce
- Mont Valérien
- Cité de l' Architecture
- Musée de l' Immigration
- Musée de Cluny
- PariStar Tour
- Albert Kahn
- BNF, Richelieu
- Citeco
- Palais Galliera
- Atelier des Lumieres
- Hotel de la Marine
- Paris Star Tour
- Au Printemps
- Musée Carnavalet
- Fondation VUITTON
- La Bourse et l'ART
- Libération Paris
- Molière
- Paris Star Tour
- Christo
- Street Art
- Charlie Chaplin
- Musée de la Police
- Le Grand Palais
- Paris Star Tour
- Mosquée de Paris
- Musée Marmottan
- Conseil d'Etat
- Musée de la Musique
- Paris La Défense
- Stade de France
- Paris Star tour
- Canal Suez
- Chateau de Vincennes
- Louis Vuitton
- Monnaie de Paris
- Arts Forains
- Chateaubriand
- Palais Garnier
- Musée Maillol
- Le Panthéon
- Club Vidèo
- Gastronomie
- Repas Fin d'Année 2023
- Repas Fin d'Année 2022
- Repas Ecole Hoteliere 2022
- Repas Fin d'Année 2021
- Repas Ecole Hoteliere 2020
- Repas Fin d'Année 2019
- Repas Ecole Hoteliere 2019
- Repas Fin d'Année 2018
- Repas Ecole Hoteliere 2018
- Repas Fin d'Année 2017
- Repas Ecole Hoteliere 2017
- Repas Fin d'Année 2016
- Repas Ecole Hoteliere 2016
- Repas Fin d'Année 2015
- Conférences
- Nos Talents, Leur Histoire
- Mots Croissés
- Faisons le Point
- La Cave de PASCAL
- Le Golf
* Nouveautés

 L' Intelligence Artificielle
L' Intelligence Artificielle
Compte-rendu de la réunion scientifique du 14 Avril 2023 à Paris 15
chez INCEPTO sur l’Intelligence Artificielle (IA).
Nous nous sommes réunis ce vendredi 14 Avril pour notre conférence scientifique sur l’Intelligence Artificielle organisée par INCEPTO, une start-up créée par des anciens de GE. Nous avons été reçus par le fondateur de cette société, Antoine JOMIER et par Jean-Michel MALBRANCQ qui est administrateur de la société. Aurore HARBONNIER et Stéphane MAQUAIRE les accompagnaient dans cette présentation.
Nous avons été accueillis dans leurs locaux très luxueux au dernier étage du bâtiment, avec une vue superbe sur Paris et la Seine. Ils ont une surface de bureau très spacieuse pour pouvoir accueillir encore d’autres développeurs.
 ;
; 
Accueil très organisé avec un poste de sécurité à l’entrée du bâtiment - zone d’attente de votre contact qui vient vous chercher pour vous rendre vers sa société.
 ;
; 
Nous étions 20 participants à cette rencontre qui fut très intéressante car l’IA est depuis plusieurs mois très commentée par les médias.
 ;
; 
De gauche à droite et debout : S. Maquaire, A. Jomier, JM Malbrancq, A. Harbonnier
Que dire de l’Intelligence Artificielle (IA) :
Ici, l’IA se met au service des réseaux de coraux pour aider à les reconstituer, là elle révolutionne la presse, ailleurs elle repère et compte les populations d’insectes pour protéger l’environnement, ou encore elle contribue à fluidifier la circulation des véhicules dans les villes modernes. On sait depuis longtemps qu’elle a bouleversé la finance et que le marketing ne peut quasiment plus fonctionner sans elle. Demain, elle transformera encore plus profondément le monde et toute la diversité de l’activité humaine qu’elle soit économique ou sociale. Nous ne sommes qu’au début de la révolution de l’Intelligence Artificielle. Pour que cette transformation contribue à rendre notre société meilleure, les entreprises, grandes et petites, les administrations, les associations, ont besoin d’ingénieurs, de managers et de cadres supérieurs formés dans cette perspective. Les futurs acteurs de l’IA et des Data devront faire preuve de compétences scientifiques et techniques mais également avoir une compréhension élargie de l’IA.
De nouveaux langages et métiers sont en développement :
AI Engineer, Machine Learning Engineer, Data Manager, Data Analyst, chef de projet IA, IA Business Developer ou IA Manager.
Les nouveaux métiers de l’IA et des Big Data explosent en entreprise. De nouvelles activités émergent ou seront bientôt mises sur le marché : la voiture autonome automatisée, l’assistance au diagnostic médical, l’optimisation de la relation client… Elles nécessitent de tels profils toujours en plus grand nombre.

Evidemment nos anciens collègues de GE, avec à sa tête Antoine JOMIER, le fondateur d’INCEPTO, se sont principalement orientés dans l’assistance au diagnostic médical.
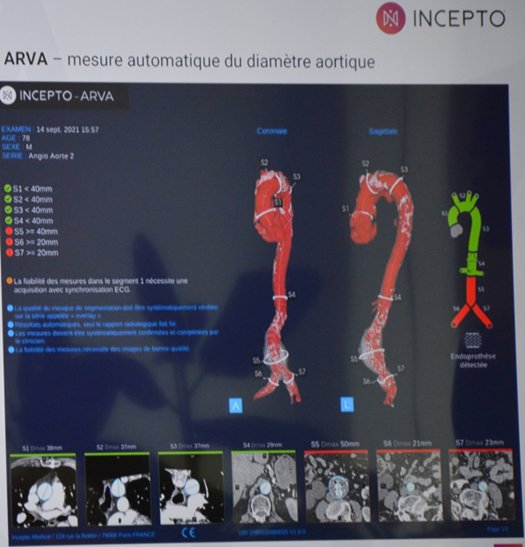
Applications cliniques de deep learning
1°) La détection

- Objectif : prédire la localisation des lésions potentielles, souvent sous la forme de boîtes englobantes
- CNN : réseaux de neurones convolutifs

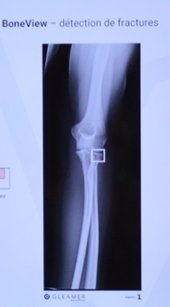
Applications cliniques de deep learning
2°) Détection + classification :
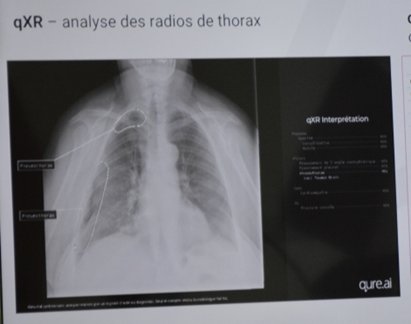
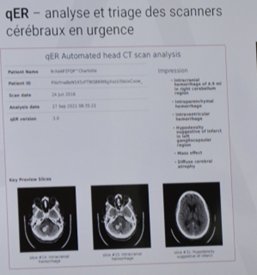
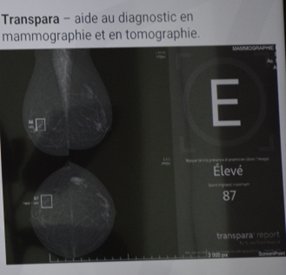
Applications cliniques de deep learning
3°) Segmentation :
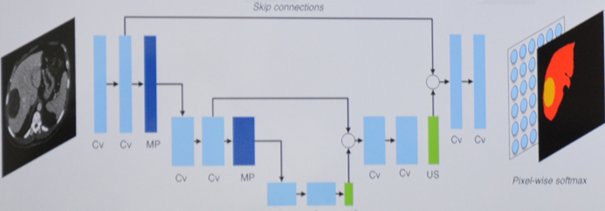
Focus deep learning
Les réseaux de neurones convolutifs (CNN) :
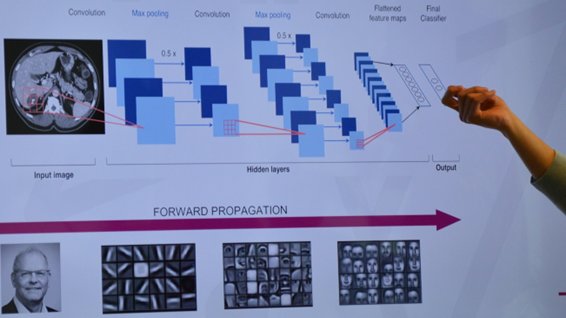
Les réseaux de neurones convolutifs ont une méthodologie similaire à celle des méthodes traditionnelles d'apprentissage supervisé : ils reçoivent des images en entrée, détectent les features de chacune d'entre elles, puis entraînent un classifieur dessus.
Cependant, les features sont apprises automatiquement ! Les CNN réalisent eux-mêmes tout le travail fastidieux d'extraction et description de features : lors de la phase d'entraînement, l'erreur de classification est minimisée afin d'optimiser les paramètres du classifieur ET les features ! De plus, l'architecture spécifique du réseau permet d'extraire des features de différentes complexités, des plus simples au plus sophistiquées. L'extraction et la hiérarchisation automatiques des features, qui s'adaptent au problème donné, constituent une des forces des réseaux de neurones convolutifs : plus besoin d'implémenter un algorithme d'extraction "à la main", comme SIFT ou Harris-Stephens.
Contrairement aux techniques d'apprentissage supervisé, les réseaux de neurones convolutifs apprennent les features de chaque image. C'est là que réside leur force : les réseaux font tout le travail d'extraction de features automatiquement, contrairement aux techniques d'apprentissage.
Aujourd'hui, les réseaux de neurones convolutifs aussi appelés CNN ou ConvNet pour Convolutional Neural Network, sont toujours les modèles les plus performants pour la classification d'images.
Optimisation Scheme (supervision) :

Programmation Scheme / Récursivité :
La récursivité, c'est lorsqu'une procédure s'appelle elle-même. Il faut impérativement prévoir une condition de fin, sans quoi l'appel récursif ne se termine jamais.
Scheme est un langage de programmation fonctionnelle qui procède de façon algorithmique, c'est-à-dire qu’il établit une méthode propre à la résolution d'un problème en détaillant les étapes de calcul. L'intérêt étant de le rendre utilisable pour toute donnée considérée.
Pour résoudre un problème on devra d’abord spécifier les informations qui entreront en jeu dans sa résolution, à savoir :
1. Les données, celles qui sont fournies avant l'exécution du programme et qui serviront de base aux calculs.
2. Les résultats que renverront ces calculs.
3. Les relations qui lient ces données avec les résultats
Focus deep learning
Le dataset :
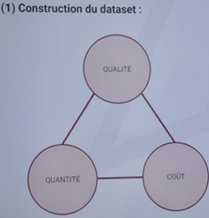

Pour bien comprendre la relation et les différences qui existent entre Machine Learning et science des données, il est nécessaire de s’intéresser au processus employé en Data Science.
Mener à bien un projet de Data Science implique de suivre les différentes étapes qui composent son cycle de vie :
1. Définition d’un objectif principal : qu’il s’agisse d’augmenter les ventes, de simplifier une procédure ou de détecter une anomalie, le projet doit répondre à une problématique présente au sein de l’entreprise ;
2. Collecte des données : identifier les différentes sources de données pertinentes selon le but à atteindre ;
3. Nettoyage : les données brutes sont transformées pour parvenir à un format exploitable par les datas scientists (scientifiques de la donnée) ;
4. Exploitation des données : comprendre les liens entre data (patterns) ;
4. Exploitation des données : comprendre les liens entre data (patterns) ;
6. Déploiement et ajustement du modèle : le projet est appliqué dans le monde réel et adapté au fil du temps.
Challenge et limites:
limites:
• Les données en pratique : non-trivial
• Image + résultats ne sont pas parfois suffisants !
• Pour un problème « simple » on s’approche des performances des radiologues
Challenge
Les questions les plus fréquentes :
• Comment valider et évaluer un modèle ?
• Quelle confiance accorder au résultat ?
• Sur quoi s’appuie un réseau pour prendre une décision ?
L’apprentissage est purement statistique sans garantie théorique ?
+
Forte dépendance aux données
Cette conférence scientifique s’est terminée par un amical pot de l’amitié que nous avons eu plaisir de prendre ensemble.
Merci à Antoine JOMIER et à son équipe de nous avoir si gentiment accueillis dans leurs superbes locaux parisiens près de la tour Eiffel.

De gauche à droite :
Stéphane Maquaire, Antoine Jomier, Jean Michel Malbrancq, Aurore Harbonnier
Glossaire :
Deep Learning : Le deep learning ou apprentissage profond est un type d'intelligence artificielle dérivé du machine learning (apprentissage automatique) où la machine est capable d'apprendre par elle-même, contrairement à la programmation où elle se contente d'exécuter à la lettre des règles prédéterminées.
Le deep Learning s'appuie sur un réseau de neurones artificiels s'inspirant du cerveau humain. Ce réseau est composé de dizaines voire de centaines de « couches » de neurones, chacune recevant et interprétant les informations de la couche précédente. Le système apprendra par exemple à reconnaître les lettres avant de s'attaquer aux mots dans un texte, ou déterminera s'il y a un visage sur une photo avant de découvrir de quelle personne il s'agit.
À chaque étape, les « mauvaises » réponses sont éliminées et renvoyées vers les niveaux en amont pour ajuster le modèle mathématique. Au fur et à mesure, le programme réorganise les informations en blocs plus complexes. Lorsque ce modèle est par la suite appliqué à d'autres cas, il est normalement capable de reconnaître un chat sans que personne ne lui ait jamais indiqué qu'il n'ait jamais appris le concept de chat. Les données de départ sont essentielles : plus le système accumule d'expériences différentes, plus il sera performant.
Machine learning : Traduit par l’expression “apprentissage automatique” en français, le Machine Learning se définit comme un programme informatique conçu pour donner la capacité aux ordinateurs d’apprendre par eux-mêmes, sans avoir été programmés en amont. Cela passe par la mise en place d'algorithmes et par l’utilisation de probabilités statistiques. La machine s'entraîne alors à apprendre, à réagir lorsqu’elle se trouve face à un problème et à agir selon différents scénarios, plutôt que de suivre une suite d’instructions de façon stricte.
Dans le domaine médical, pour engager des traitements plus efficaces et mieux évaluer le pronostic vital, tout l'enjeu est d'identifier précisément le type de tumeur cérébrale auquel on a affaire. Classiquement, le diagnostic se fait par histologie, c'est-à-dire par l'observation au microscopiques des tissus biologiques qui ont pu être prélevés
Cette méthode repose sur l'analyse d'irrégularités cellulaires subtiles, si bien que le diagnostic final peut varier sensiblement d'un médecin à l'autre. En outre, plusieurs types de tumeurs peuvent partager des caractéristiques histologiques sans pour autant évoluer de la même façon.
C'est pourquoi David Capper et ses collègues se sont tournés vers une autre méthode d'analyse basée sur des marqueurs moléculaires : celle de la méthylation de l'ADN des cellules tumorales, soit l'addition de groupes méthyles sur l'ADN. Ce genre de diagnostic, qui a l'avantage d'être totalement objectif, ne se fait pourtant pas de façon systématique, par manque de moyens, bien que les efforts aillent dans ce sens. L'OMS conseille depuis 2016 de combiner histologie et analyse moléculaire pour examiner certains types de tumeurs du cerveau.
Souhaitant standardiser le processus, les chercheurs ont entraîné un ordinateur à analyser et classer les tumeurs cérébrales en différentes catégories selon leurs profils de méthylation, grâce au machine learning, un champ d'étude relevant de l'intelligence artificielle. Leur système améliore la précision d'un diagnostic histologique ou moléculaire classique. En effet, 12 % des tumeurs sur les 1104 cas étudiés ont été changées de catégorie, suivant les recommandations de l'ordinateur.
Autrement dit, la Data Science facilite la prise de décisions stratégiques des organisations à partir de données et, pour y arriver, elle s'appuie sur un ensemble de techniques dont l’Intelligence Artificielle, le Machine Learning et le Deep Learning.Le Machine Learning est donc considéré comme une technique au service de la Data Science, car il est le maillon essentiel de l’étape de modélisation des données.
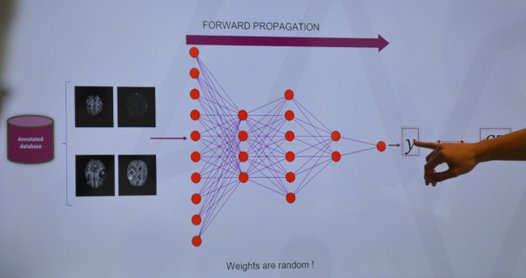
Rappel sur les réseaux de neurones :
Les principaux éléments à retenir sont les suivants :
• Un réseau de neurones est un système composé de neurones, généralement répartis en plusieurs couches connectées entre elles ;
• Un tel système s'utilise pour résoudre divers problèmes statistiques, mais nous ne nous intéressons ici qu'au problème de classification (très courant). Dans ce cas, le réseau calcule à partir de l'entrée un score (ou probabilité) pour chaque classe. La classe attribuée à l'objet en entrée correspond à celle de score le plus élevé ;
• Chaque couche reçoit en entrée des données et les renvoie transformées. Pour cela, elle calcule une combinaison linéaire puis applique éventuellement une fonction non-linéaire, appelée fonction d'activation. Les coefficients de la combinaison linéaire définissent les paramètres (ou poids) de la couche ;
• Un réseau de neurones est construit en empilant les couches : la sortie d'une couche correspond à l'entrée de la suivante ;
• Cet empilement de couches définit la sortie finale du réseau comme le résultat d'une fonction différentiable de l'entrée ;
• La dernière couche calcule les probabilités finales en utilisant pour fonction d'activation la fonction logistique (classification binaire) ou la fonction softmax (classification multi-classes) ;
• Une fonction de perte (loss function) est associée à la couche finale pour calculer l'erreur de classification. Il s'agit en général de l'entropie croisée ;
• Les valeurs des poids des couches sont apprises par rétropropagation du gradient : on calcule progressivement (pour chaque couche, en partant de la fin du réseau) les paramètres qui minimisent la fonction de perte régularisée. L'optimisation se fait avec une descente du gradient stochastique